TRADITIONAL MONITORING NOTIFIES YOU WHEN SOMETHING IS BROKEN
Every HPC shop monitors its systems….it’s basic telemetry across a select few of the thousands of parameters available from every machine in your cluster. Once a system parameter crosses a predetermined static threshold, an alert is sounded that something is broken. System administrators jump into reactive mode in an attempt to address the alert.
What tools do they have? Monitoring either provides administrators with a low-resolution glimpse of a limited number of key parameters or an overwhelming explosion of billions of data points from thousands of machines.
Either way, you’re relying on the best guess from your HPC “guru,” who’s incapable of consuming the billions of data points and relationships inherent in the telemetry. The experience and insight of the HPC guru is a critical component in the success of an HPC system, but a human cannot derive insight from billions of data points, nor can they take action in real time.
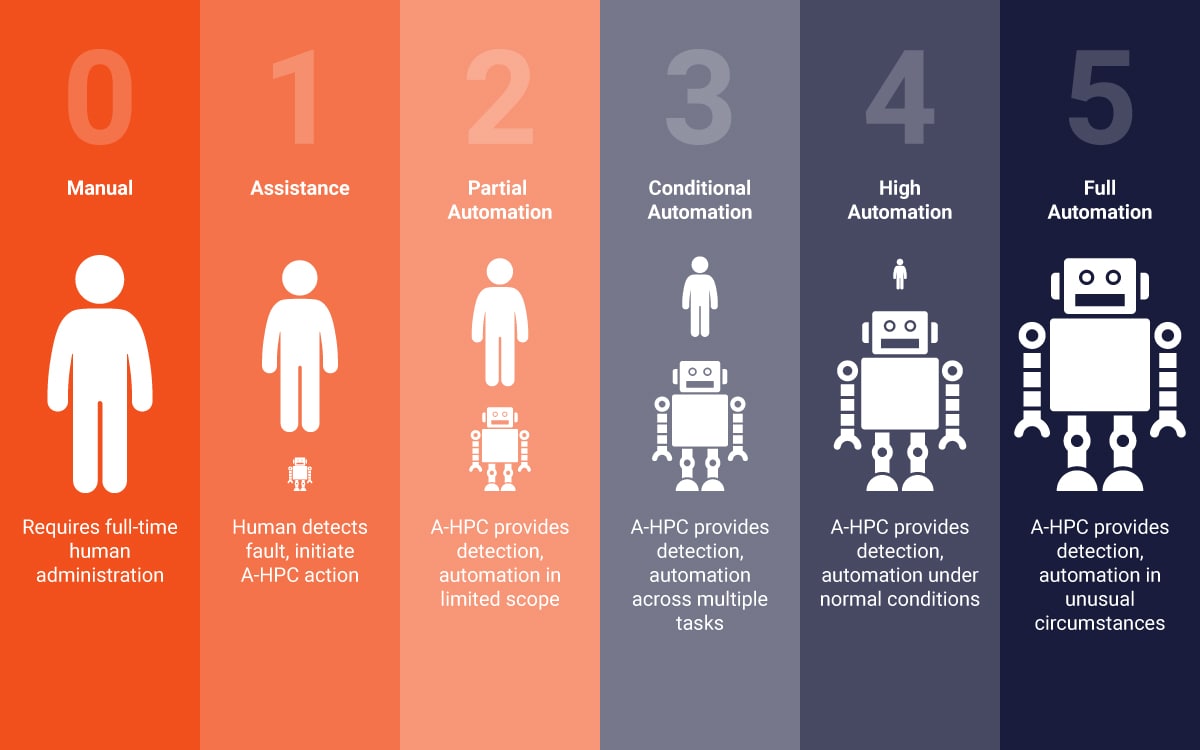
AutonomousHPC NOTIFIES YOU WHEN SOMETHING IS FIXED
AutonomousHPC combines the insight of the HPC guru with the power of the modern data warehouse, analytics and machine-learning system. A-HPC collects and warehouses 1363 unique streams of telemetry from each node that runs Spectrum Scale, Spectrum Protect, and/or Linux. A small cluster can generate billions of data points each day. AutonomousHPC doesn’t replace the insight of your guru; it provides powerful tools to automate the administrative work.